Pallas 快速入門#
Pallas 是 JAX 的擴充功能,可讓您撰寫用於 GPU 和 TPU 的自訂核心。Pallas 允許您使用相同的 JAX 函數和 API,但在較低的抽象層級運作。
具體來說,Pallas 要求使用者思考記憶體存取,以及如何在硬體加速器中的多個運算單元之間劃分運算。在 GPU 上,Pallas 降低到 Triton;在 TPU 上,Pallas 降低到 Mosaic。
讓我們深入探討一些範例。
注意:Pallas 仍然是一個實驗性 API,變更可能會破壞您的程式碼!
Pallas 中的 Hello world#
from functools import partial
import jax
from jax.experimental import pallas as pl
import jax.numpy as jnp
import numpy as np
我們首先在 Pallas 中撰寫「hello world」,一個將兩個向量相加的核心。
def add_vectors_kernel(x_ref, y_ref, o_ref):
x, y = x_ref[...], y_ref[...]
o_ref[...] = x + y
Ref 類型
讓我們剖析一下這個函數。與您可能撰寫過的大多數 JAX 函數不同,它不接收 jax.Array 作為輸入,也不傳回任何值。相反地,它接收 Ref 物件作為輸入,這些物件代表記憶體中的可變緩衝區。請注意,我們也沒有任何輸出,但我們被給定一個 o_ref,它對應於所需的輸出。
從 Ref 讀取
在主體中,我們首先從 x_ref 和 y_ref 讀取,由 [...] 指示(省略號表示我們正在讀取整個 Ref;或者我們也可以使用 x_ref[:])。像這樣從 Ref 讀取會傳回 jax.Array。
寫入 Ref
然後我們將 x + y 寫入 o_ref。在 JAX 中,變更歷史上不受支援 – jax.Array 是不可變的!Ref 是新的(實驗性)類型,允許在某些情況下進行變更。我們可以將寫入 Ref 解釋為變更其底層緩衝區。
因此,我們撰寫了我們稱之為「核心」的東西,我們將其定義為一個程式,它將作為加速器上的原子執行單元執行,而無需與主機進行任何互動。我們如何從 JAX 計算中調用它?我們使用 pallas_call 高階函數。
@jax.jit
def add_vectors(x: jax.Array, y: jax.Array) -> jax.Array:
return pl.pallas_call(
add_vectors_kernel,
out_shape=jax.ShapeDtypeStruct(x.shape, x.dtype)
)(x, y)
add_vectors(jnp.arange(8), jnp.arange(8))
Array([ 0, 2, 4, 6, 8, 10, 12, 14], dtype=int32)
pallas_call 將 Pallas 核心函數提升為可以作為較大型 JAX 程式一部分調用的操作。但是,要做到這一點,它需要更多細節。在這裡,我們指定 out_shape,一個具有 .shape 和 .dtype(或其列表)的物件。out_shape 決定了我們 add_vector_kernel 中 o_ref 的形狀/dtype。
pallas_call 傳回一個接收和傳回 jax.Array 的函數。
這裡實際發生了什麼?
到目前為止,我們已經描述了如何思考 Pallas 核心,但我們實際完成的是,我們正在撰寫一個非常接近運算單元執行的函數,因為值被載入到記憶體階層結構的最內層(最快)部分。
在 GPU 上,x_ref 對應於高頻寬記憶體 (HBM) 中的一個值,當我們執行 x_ref[...] 時,我們正在將值從 HBM 複製到靜態 RAM (SRAM)(一般來說,這是一個成本高昂的操作!)。然後我們使用 GPU 向量運算來執行加法,然後將 SRAM 中的結果值複製回 HBM。
在 TPU 上,我們做一些稍微不同的事情。在核心執行之前,我們會先將值從 HBM 提取到 SRAM。x_ref 因此對應於 SRAM 中的一個值,當我們執行 x_ref[...] 時,我們正在將值從 SRAM 複製到暫存器。然後我們使用 TPU 向量運算來執行加法,然後將結果值複製回 SRAM。在核心執行後,SRAM 值會被複製回 HBM。
我們正在撰寫特定於後端的 Pallas 指南。敬請期待!
Pallas 程式設計模型#
在我們的「hello world」範例中,我們撰寫了一個非常簡單的核心。它利用了我們 8 個大小的陣列可以舒適地放入硬體加速器的 SRAM 中的事實。在大多數現實世界的應用程式中,情況並非如此!
撰寫 Pallas 核心的一部分是思考如何取得位於高頻寬記憶體(HBM,也稱為 DRAM)中的大型陣列,並表達對可以放入 SRAM 的這些陣列「區塊」進行運算的計算。
網格範例#
為了自動「劃分」輸入和輸出,您需要為 pallas_call 提供 grid 和 BlockSpec。
grid 是一個整數元組(例如 ()、(2, 3, 4) 或 (8,)),指定了迭代空間。例如,網格 (4, 5) 將有 20 個元素:(0, 0), (0, 1), ..., (0, 4), (1, 0), ..., (3, 4)。我們針對每個元素執行一次核心函數,這是一種單程式多資料 (SPMD) 程式設計風格。
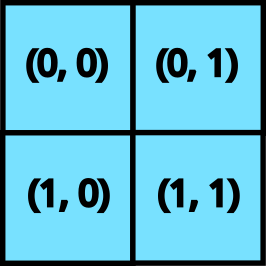
2D 網格
當我們為 pallas_call 提供 grid 時,核心會執行 prod(grid) 次。這些調用中的每一個都稱為「程式」。為了存取核心目前正在執行的程式(即網格的哪個元素),我們使用 program_id(axis=...)。例如,對於調用 (1, 2),program_id(axis=0) 傳回 1,program_id(axis=1) 傳回 2。
以下是一個使用 grid 和 program_id 的核心範例。
def iota_kernel(o_ref):
i = pl.program_id(0)
o_ref[i] = i
我們現在使用 pallas_call 和額外的 grid 參數來執行它。在 GPU 上,我們可以像這樣直接調用核心
# GPU version
def iota(size: int):
return pl.pallas_call(iota_kernel,
out_shape=jax.ShapeDtypeStruct((size,), jnp.int32),
grid=(size,))()
iota(8)
Array([0, 1, 2, 3, 4, 5, 6, 7], dtype=int32)
TPU 區分向量和純量記憶體空間,在這種情況下,輸出必須放置在純量記憶體 (TPUMemorySpace.SMEM) 中,因為 i 是一個純量。如需更多詳細資訊,請閱讀 TPU 及其記憶體空間。若要在 TPU 上調用上述核心,請執行
# TPU version
from jax.experimental.pallas import tpu as pltpu
def iota(size: int):
return pl.pallas_call(iota_kernel,
out_specs=pl.BlockSpec(memory_space=pltpu.TPUMemorySpace.SMEM),
out_shape=jax.ShapeDtypeStruct((size,), jnp.int32),
grid=(size,))()
iota(8)
網格語意#
在 GPU 上,每個程式都在單獨的執行緒上平行執行。因此,我們需要考慮寫入 HBM 時的競爭條件。一個合理的方法是以這樣一種方式撰寫我們的核心,即不同的程式寫入 HBM 中的不相交位置,以避免這些平行寫入。另一方面,平行化計算是我們如何快速執行矩陣乘法等運算的方法。
相反地,TPU 的運作方式類似於非常寬的 SIMD 機器。一些 TPU 模型包含多個核心,但在許多情況下,TPU 可以被視為單執行緒處理器。TPU 上的網格可以在平行和循序維度的組合中指定,其中循序維度保證會循序執行。
您可以在 網格,又名迴圈中的核心 和 值得注意的屬性和限制 中閱讀更多詳細資訊。
區塊規格範例#
考慮到 grid 和 program_id,Pallas 提供了一個抽象概念,可以處理在許多核心中看到的一些常見索引模式。為了建立直覺,讓我們嘗試實作矩陣乘法。
在 Pallas 中實作矩陣乘法的一個簡單策略是遞迴地實作它。我們知道我們的底層硬體支援小型矩陣乘法(使用 GPU 和 TPU tensorcore),因此我們只需用較小的矩陣乘法來表示大型矩陣乘法即可。
假設我們有輸入矩陣 \(X\) 和 \(Y\),並且正在計算 \(Z = XY\)。我們首先將 \(X\) 和 \(Y\) 表示為區塊矩陣。\(X\) 將具有「列」區塊,而 \(Y\) 將具有「行」區塊。
我們的策略是,因為 \(Z\) 也是一個區塊矩陣,我們可以為 Pallas 核心中的每個程式分配一個輸出區塊。計算每個輸出區塊對應於在 \(X\) 的「列」區塊和 \(Y\) 的「行」區塊之間執行較小的矩陣乘法。
為了表達這種模式,我們使用 BlockSpec。 BlockSpec 為每個輸入和輸出指定區塊形狀,以及一個「索引映射」函數,該函數將一組程式索引映射到區塊索引。
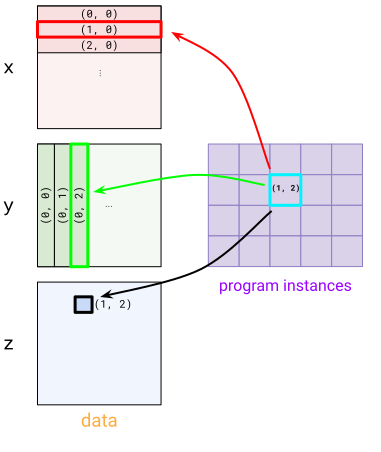
BlockSpec 的視覺化
對於一個具體範例,假設我們想要將兩個 (1024, 1024) 矩陣 x 和 y 相乘,以產生 z,並且想要以 4 種方式平行化計算。我們將 z 分成 4 個 (512, 512) 區塊,其中每個區塊都使用 (512, 1024) x (1024, 512) 矩陣乘法計算。為了表達這一點,我們首先使用 (2, 2) 網格(每個程式一個區塊)。
對於 x,我們使用 BlockSpec((512, 1024), lambda i, j: (i, 0)) – 這將 x 劃分為「列」區塊。為了查看這一點,請查看程式實例 (1, 0) 和 (1, 1) 如何在 x 中選擇 (1, 0) 區塊。對於 y,我們使用轉置版本 BlockSpec((1024, 512), lambda i, j: (0, j))。最後,對於 z,我們使用 BlockSpec((512, 512), lambda i, j: (i, j))。
這些 BlockSpec 透過 in_specs 和 out_specs 傳遞到 pallas_call 中。
有關 BlockSpec 的更多詳細資訊,請參閱 BlockSpec,又名如何將輸入分塊。
在底層,pallas_call 將自動將您的輸入和輸出劃分為 Ref,用於將傳遞到核心的每個區塊。
def matmul_kernel(x_ref, y_ref, z_ref):
z_ref[...] = x_ref[...] @ y_ref[...]
def matmul(x: jax.Array, y: jax.Array):
return pl.pallas_call(
matmul_kernel,
out_shape=jax.ShapeDtypeStruct((x.shape[0], y.shape[1]), x.dtype),
grid=(2, 2),
in_specs=[
pl.BlockSpec((x.shape[0] // 2, x.shape[1]), lambda i, j: (i, 0)),
pl.BlockSpec((y.shape[0], y.shape[1] // 2), lambda i, j: (0, j))
],
out_specs=pl.BlockSpec(
(x.shape[0] // 2, y.shape[1] // 2), lambda i, j: (i, j),
)
)(x, y)
k1, k2 = jax.random.split(jax.random.key(0))
x = jax.random.normal(k1, (1024, 1024))
y = jax.random.normal(k2, (1024, 1024))
z = matmul(x, y)
np.testing.assert_allclose(z, x @ y)
請注意,這是一個非常幼稚的矩陣乘法實作,但可以將其視為各種最佳化的起點。讓我們為矩陣乘法新增一個額外功能:融合激活。實際上非常容易!只需將高階激活函數傳遞到核心即可。
def matmul_kernel(x_ref, y_ref, z_ref, *, activation):
z_ref[...] = activation(x_ref[...] @ y_ref[...])
def matmul(x: jax.Array, y: jax.Array, *, activation):
return pl.pallas_call(
partial(matmul_kernel, activation=activation),
out_shape=jax.ShapeDtypeStruct((x.shape[0], y.shape[1]), x.dtype),
grid=(2, 2),
in_specs=[
pl.BlockSpec((x.shape[0] // 2, x.shape[1]), lambda i, j: (i, 0)),
pl.BlockSpec((y.shape[0], y.shape[1] // 2), lambda i, j: (0, j))
],
out_specs=pl.BlockSpec(
(x.shape[0] // 2, y.shape[1] // 2), lambda i, j: (i, j)
),
)(x, y)
k1, k2 = jax.random.split(jax.random.key(0))
x = jax.random.normal(k1, (1024, 1024))
y = jax.random.normal(k2, (1024, 1024))
z = matmul(x, y, activation=jax.nn.relu)
np.testing.assert_allclose(z, jax.nn.relu(x @ y))
總之,讓我們重點介紹 Pallas 的一個酷炫功能:它與 jax.vmap 組成!若要將此矩陣乘法轉換為批次版本,我們只需要 vmap 它即可。
k1, k2 = jax.random.split(jax.random.key(0))
x = jax.random.normal(k1, (4, 1024, 1024))
y = jax.random.normal(k2, (4, 1024, 1024))
z = jax.vmap(partial(matmul, activation=jax.nn.relu))(x, y)
np.testing.assert_allclose(z, jax.nn.relu(jax.vmap(jnp.matmul)(x, y)))