Pallas 設計#
在這份文件中,我們將解釋最初的 Pallas 設計。這是早期設計決策的快照,Pallas 的特定 API 可能自那時起已變更。
簡介#
JAX 正被用於各種工作負載,從大規模機器學習到科學計算。JAX 的成功故事與其說是 JAX 的成功故事,不如說是 XLA 的成功故事,XLA 是 JAX 主要的編譯器目標 – XLA 編譯 JAX 程式以用於加速器,並使 JAX 能夠擴展到最大的 ML 模型。JAX 在 XLA 的表示形式 HLO 中描述邏輯計算。HLO 描述了計算如何在邏輯上發生,而不是物理上如何發生。給定一個邏輯 HLO 計算,XLA 決定該計算如何在物理上執行。對於各種 ML 應用程式,XLA 在編譯使用者程式方面做得很好,但不可避免地,有些使用者會遇到 XLA 的限制。在這些情況下,我們需要提供「逃生出口」,讓專家能夠編寫手動調整的核心,使其在當時的效能優於 XLA。此外,ML 系統研究的進展需要一些時間才能納入 XLA,而使用者通常希望搶先使用。隨著時間的推移,編譯器可以納入手動調整核心所實驗證明的最佳化。
XLA 確實提供了 CustomCall 機制作為逃生出口,但它要求使用者編寫 C++,並且在 GPU 上,它要求使用者學習 CUDA 程式設計模型。對於許多機器學習 GPU 核心(例如矩陣乘法),CUDA 程式設計模型可以說是過於低階,即使是專家使用者也很難使用 CUDA 實作高效的矩陣乘法或多頭注意力機制。不僅如此,JAX 使用者通常熟悉 Python 和 NumPy 風格的陣列程式設計,這不涉及編寫任何 C++ 或思考 GPU 平行處理。所有流行的機器學習框架都共享這個想法:使用高階運算(例如 matmul 或 convolution)來操作(通常是)陣列。不幸的是,這表示透過 CustomCall 實作自訂運算是一項很大的投資,可能涉及學習 C++ 和/或 GPU 程式設計。
Triton 是 OpenAI 建構和維護的 GPU 編譯器,已在 ML 編譯器世界中掀起風暴。Triton 兼具兩者的優點:用於 GPU 核心的基於陣列的程式設計模型。透過 Torch Inductor 程式庫,Triton 是 PyTorch 2.0 中 torch.compile 的主要程式碼產生途徑。Triton 主動隱藏 GPU 程式設計的某些方面,以提供更易於存取的程式設計模型,該模型可以從 Python 使用,並從更高階的表示形式產生最佳化程式碼。雖然 GPU 比 Triton 提供的功能更靈活,但在 ML 領域中,Triton 對於許多應用程式來說似乎已足夠具備表達力。
在這份文件中,我們描述了 Pallas,這是 JAX 的一個擴展,它使用類似 Triton 的模型,為 GPU 和 TPU 啟用核心程式設計。基於 JAX 的核心語言具有多項優勢
雖然 Triton 向使用者公開了類似 TPU 的程式設計模型,也就是說,為 L1 快取中的陣列圖塊編寫程式,但它對於 GPU 來說非常專業,以至於我們無法直接為 TPU 編譯 Triton。例如,Triton 提供原子操作,專門用於處理不一定在 TPU 上有意義的平行寫入。更高階的前端可以抽象化平台的細節,同時僅呈現基於圖塊的程式設計模型。因此,這些核心將可在不同的硬體平台上移植。
JAX 作為數值計算的基於追蹤的前端,既成熟又廣泛使用。透過將核心程式設計語言嵌入到 JAX 本身中,我們可以重複使用 JAX 的追蹤基礎架構,並提供使用者已經熟悉的類似 NumPy 的前端。
JAX 轉換是其成功的關鍵,它允許使用者表達簡單的程式,但將它們轉換以實現複雜的功能。我們可以利用相同的轉換(vmap、jvp 等)來轉換使用者編寫的核心。
開放性問題是:JAX 是否完全適合作為核心語言?我們認為是。Triton 證明了陣列程式設計語言對於編寫 GPU 核心是可行的,而 JAX 正是如此。JAX 也已被證明是編譯器和程式轉換的彈性前端。
我們如下描述 Pallas:我們首先描述擴展 JAX 以支援編寫自訂核心的方式。然後,我們展示如何將 Pallas 降低到 Triton 和 Mosaic。最後,我們描述透過 JAX 轉換來轉換 Pallas 核心的現有和潛在方式。
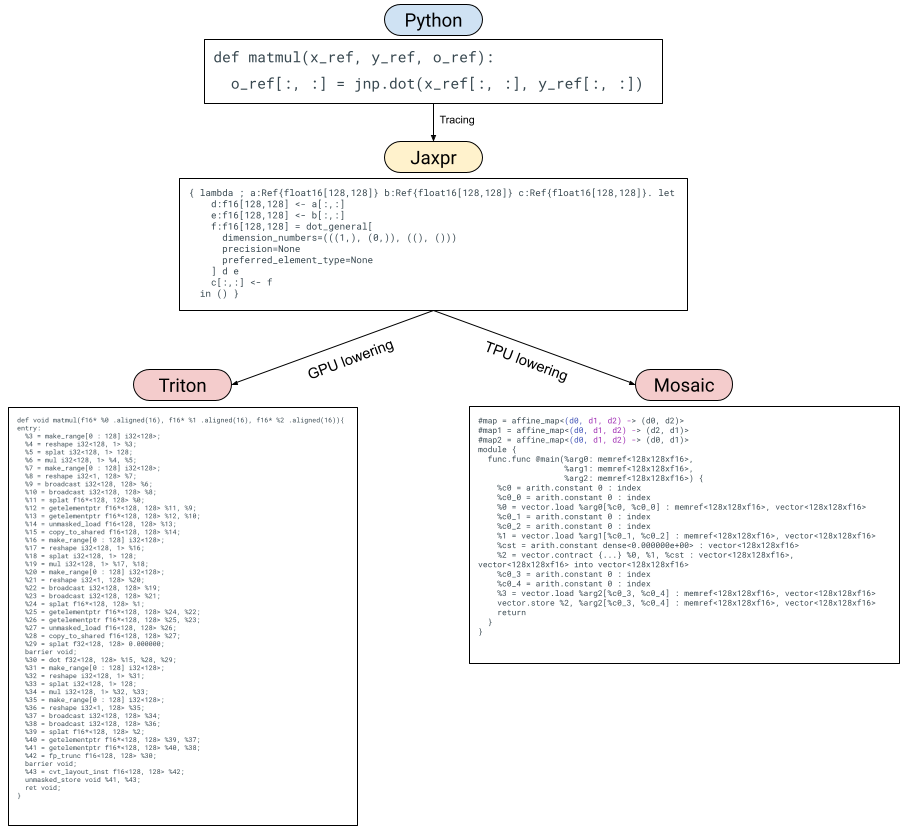 Pallas 降低路徑的可視化
Pallas 降低路徑的可視化
Pallas:為核心擴展 JAX#
我們想提出的重點是,Pallas 只是 JAX,但有一些擴展
使用者現在在其 JAX 程式碼中使用稱為
Ref的參考型別。這讓使用者可以更精確地控制 JAX 中的記憶體存取和佈局,並且將更緊密地對應物理佈局。使用者使用 JAX 原始運算的子集以及一組 Pallas 特定的原始運算來編寫其 JAX 程式。
使用者透過特殊的
pallas_call高階函數將其 Pallas 核心嵌入到外部 JAX 程式中,該函數在映射中執行核心。它類似於pmap或shard_map,但具有對共享記憶體的參考。
我們將透過範例逐一介紹這三個擴展。
請注意,這些 API 仍處於實驗階段,可能會有所變更。
參考型別#
讓我們看一下用於新增兩個向量的 Pallas 程式範例
import jax
import jax.numpy as jnp
from jax.experimental import pallas as pl
def add_kernel(x_ref, y_ref, o_ref):
# In this code, `x_ref`, `y_ref` and `o_ref` are (8,)-shaped `Ref`s
x = x_ref[:]
y = y_ref[:]
o_ref[:] = x + y
x, y = jnp.arange(8), jnp.arange(8, 16)
add = pl.pallas_call(add_kernel, out_shape=jax.ShapeDtypeStruct((8,), jnp.int32))
add(x, y)
與常規 JAX 程式不同,add_kernel 不接收不可變陣列引數。相反地,它會提供參考,可以使用類似 NumPy 的語法從中讀取並就地更新。Ref 並非 Pallas 特有的概念 – 它們被引入 JAX 以表示具狀態的計算。但是,我們可以在編寫處理可變記憶體的核心時也利用它們。
Pallas 核心不僅接收對應於核心輸入的 Ref,而且還接收輸出的 Ref(在 pallas_call 中透過 out_shape 指定)。Ref 是特殊的型別,在未先從中讀取的情況下,無法傳遞到通常的 JAX 原始運算集中。當您從 Ref 讀取時,您會得到 JAX Array 型別的輸出,並且您必須將 Array 寫入到 Ref 中。
從 Refs 讀取/寫入 Refs#
從 Ref 讀取對應於將陣列載入到記憶體階層的最低層級(GPU 上的 L1 快取和 TPU 上的向量暫存器)。寫入到 Ref 是類似的。
def f(x_ref, o_ref):
# Using vanilla Python indexing
x = x_ref[0, 2:5, :]
# Or via Numpy advanced int indexing
o_ref[jnp.arange(3), :] = x
# Note that in order to use NumPy advanced int indexing, you need to broadcast the indices against each other into the desired multidimensional shape:
def f(x_ref):
# Assume x_ref is (8, 4) and we want to read out a (2, 3) slice
x = x_ref[jnp.arange(2)[..., None], jnp.arange(3)[None, ...]]
可以使用類似的 __setitem__ 風格索引來完成寫入 Ref。
其他形式的索引(例如,動態切片)可以使用 pallas.load 和 pallas.store 完成,這些是新的 JAX 原始運算,旨在使從記憶體載入/儲存到記憶體中更容易。我們稍後將討論這些新的原始運算。
使用新的 Pallas 原始運算擴展 JAX#
由於 JAX 在設計時考慮了 HLO,因此 JAX 原始運算的集合緊密地反映了 HLO 運算的集合。以新的編譯器(例如 Triton 或 Mosaic)為目標表示我們可能需要使用新的編譯器特定的原始運算來補充 JAX 的原始運算。同時,我們可能無法降低所有 JAX 原始運算,因此我們需要將其限制為子集。
由於 Pallas 最初在設計時考慮了 Triton,因此我們提供了一組新的原始運算,以 Triton 程式設計模型為目標。正如我們稍後將展示的那樣,我們也可以將這些原始運算降低到 Mosaic。
pallas.load 和 pallas.store#
pallas.load 和 pallas.store 是允許從記憶體載入和儲存到記憶體的原始運算。與 __getitem__ 和 __setitem__ 不同,它們更具彈性,但代價是更冗長。具體來說,您可以使用 pallas.dynamic_slice(簡稱 pallas.ds)建構(這可能應該上游到 JAX,以便與 Ref __getitem__ 和 __setitem__ 一起使用)。
def f(x_ref, o_ref):
# Reading from memory via pallas.load
x = pl.load(x_ref, (0, slice(2, 5), slice(None)))
# Using integer indexing automatically broadcasts
x = pl.load(x_ref, (0, 2 + jnp.arange(3), slice(None)))
# You can also use `pl.dynamic_slice` (`pl.ds` for short) objects as well
pl.store(o_ref, (0, pl.ds(start=2, size=3), slice(None)), x)
pallas.load 和 pallas.store 也透過遮罩引數支援遮罩。
def f(x_ref, o_ref):
# Reading from memory via pallas.load
idx = jnp.arange(8)
mask = idx < 5
x = pl.load(x_ref, (idx,), mask=mask, other=float('-inf'))
當執行超出邊界的載入/儲存時,遮罩非常重要。遮罩的操作語意可以由編譯器決定(如果我們正確理解文件,Triton 會避免從/寫入到記憶體,如果它被遮罩)。
pallas.program_id 和 pallas.num_programs#
正如我們很快就會看到的,我們將多次執行相同的 Pallas 核心(平行或在管線中,取決於後端)。這些新的原始運算告訴我們,我們目前在核心執行中的「位置」。
pallas.program_id 接收軸引數,該引數告訴我們此核心目前在多維網格的軸中的哪個索引中執行(類似於 CUDA 程式設計中的 threadId 或 jax.pmap 中的 lax.axis_index)。請注意,我們目前借用 Triton 的「程式」術語,未來我們可能希望將其更改為 JAX 使用者更熟悉的術語。
def f(x_ref, o_ref):
i = pl.program_id(axis=0) # execution index in the first axis of the grid
o_ref[i] = jnp.exp(x_ref[i])
pallas.num_programs 也接收軸,並傳回該軸的網格大小。
請注意,雖然 program_id 和 num_programs 是 Triton 特定的術語,但它們很容易推廣到在 TPU 上也有意義。
在 Pallas 中使用 JAX 原始運算的子集#
由於我們正在編寫核心,而不是高階 HLO 程式,因此某些 JAX 原始運算可能無法在我們的底層基板中有效表示。但是,我們知道我們可以支援大多數元素級運算、簡單的點積和 JAX 控制流程。
雖然我們尚未完全映射出我們可以在 Pallas 核心中支援的所有 JAX 原始運算,但我們當然可以識別出一些不容易降低或不太可能有用的原始運算
conv_general- 卷積通常不作為底層硬體中的原始運算提供。gather/scatter- 底層編譯器可能不支援非連續記憶體讀取和寫入
使用 pallas_call 執行 Pallas 核心#
現在我們已經編寫了 Pallas 核心(又名具有 Ref 和額外 Pallas 原始運算的 JAX),我們如何在 GPU 或 TPU 上執行它們?我們使用 pallas_call,這是一個高階函數(類似於 jax.jit 和 jax.pmap),用於執行核心。
pallas_call 的簽名如下
def pallas_call(
kernel: Callable,
out_shape: Sequence[jax.ShapeDtypeStruct],
*,
in_specs: Sequence[Spec],
out_specs: Sequence[Spec],
grid: Optional[Tuple[int, ...]] = None) -> Callable:
...
當我們向 pallas_call 提供核心時,我們會提供額外資訊。第一個是 out_shape,它告訴核心輸出的外觀(pallas_call 將傳遞對應於這些輸出的 Ref 到核心以進行寫入)。其餘資訊(in_specs、out_specs 和 grid)是有關核心如何在加速器上排程的資訊。
pallas_call 的(粗略)語意如下
def pallas_call(kernel, out_shape, *, in_specs, out_specs, grid):
def execute(*args):
outputs = map(empty_ref, out_shape)
grid_indices = map(range, grid)
for indices in itertools.product(*grid_indices): # Could run in parallel!
local_inputs = [in_spec.transform(arg, indices) for arg, in_spec in
zip(args, in_specs)]
local_outputs = [out_spec.transform(arg, indices) for arg, out_spec in
zip(outputs, out_specs)]
kernel(*local_inputs, *local_outputs) # writes to outputs
return execute
具體來說,pallas_call 將「迴圈」遍歷網格迭代空間,對透過 in_specs 和 out_specs 指定的輸入和輸出套用轉換。在每次迭代中,核心將在轉換後的輸入和輸出上呼叫。請注意,迭代空間上的「迴圈」可以平行執行(例如,在 GPU 上)。pallas_call 也不能保證迭代空間上迴圈迭代的順序,只能保證迭代空間的每個成員都將被迴圈遍歷。Triton 和 Mosaic 等編譯器將具有與網格相關聯的更具體的操作語意。
轉換函數#
pallas_call 的 in_specs 和 out_specs 引數允許以某種方式轉換輸入和輸出。Pallas 目前提供的兩個選項是恆等變換(其中輸入和輸出保持不變)和 BlockSpec,它採用由迴圈索引決定的 Ref 的固定大小切片。
BlockSpec 採用 index_map 函數和 block_shape。從邏輯上講,它採用陣列並沿每個軸將其切片成 block_shape 大小的區塊。index_map 函數採用迴圈索引(來自網格索引集)並將它們映射到區塊索引。轉換函數將 Ref 轉換為 Ref 在相應區塊處的邏輯視圖。當我們在 block_shape 中的條目中指定 None 時,這對應於對該維度進行「映射」,從核心內的區塊中移除它。
class BlockSpec:
index_map: Callable[[Tuple[Int, ...]], Tuple[Int, ...]]
block_shape: Tuple[Optional[int], ...]
def transform(self, ref, *loop_indices):
block_indices = self.transform_function(loop_indices)
# Returns a view of `ref` starting at `block_indices` of shape self.block_shape
...
我們也可以想像與 pallas_call 一起使用的其他 Spec,例如,對應於重疊視窗的 Spec,以實作卷積。
Pallas 作為前端的直接優勢#
透過為核心編寫提供 JAX 前端,我們可以立即獲得一些優勢。
更彈性的前端#
首先,JAX 使用者已經習慣了使用 JAX 及其基於追蹤的轉換進行程式設計的優勢(和限制)。這表示使用者可以在編寫 Pallas 核心時使用閉包和其他熟悉的 Python 建構。這與現有的基於 AST 解析的 Triton 前端或用於 Mosaic 的 MLIR 建構器不同。例如,這使得 Pallas 比 Triton 更適合範本化。
請參閱這個範例,了解我們如何在 Python 中使用高階函數來範本化核心。
def make_kernel(eltwise_kernel):
def add(x_ref, y_ref, o_ref):
x = pl.load(x_ref, ())
y = pl.load(y_ref, ())
pl.store(o_ref, (), eltwise_kernel(x + y))
return add
kernel1 = make_kernel(lambda x: x * 2)
kernel2 = make_kernel(jnp.exp)
pl.pallas_call(kernel1, out_shape=x, grid=1)(1., 1.)
pl.pallas_call(kernel2, out_shape=x, grid=1)(1., 1.)
模擬模式#
透過將核心表示為具有 JAX 原始運算和一些新的 Pallas 原始運算的程式,我們也可以將 Pallas 程式直接降低到 StableHLO,並使用 XLA 編譯/執行它們。具體來說,pallas_call 可以實作為網格上的 lax.scan。這使我們能夠在任何 XLA 支援的平台上(甚至是 CPU!)開發 GPU 或 TPU 核心,並使用 JAX/XLA 偵錯工具(例如 jax.debug.print)對其進行偵錯。我們也可以使用更可靠且經過更好測試的 XLA 數值來驗證 Triton 和 Mosaic 編譯器的正確性。人們也可以想像擾亂 scan 排序以模擬 GPU 上發生的平行讀取和寫入。
GPU 範例#
請注意,以下所有範例僅適用於 GPU。它們將需要調整區塊大小才能在 TPU 上運作。
add#
我們修改了 add_kernel 範例,使其可以使用 BlockSpecs 在 (2,) 大小的區塊上運作。
def add_kernel(x_ref, y_ref, o_ref):
# In this code, `x_ref`, `y_ref` and `o_ref` are (2,)-shaped `Ref`s
x = x_ref[:]
y = y_ref[:]
o_ref[:] = x + y
x, y = jnp.arange(8), jnp.arange(8, 16)
add = pl.pallas_call(
add_kernel,
out_shape=jax.ShapeDtypeStruct((8,), jnp.int32),
in_specs=[
pl.BlockSpec((2,), lambda i: i),
pl.BlockSpec((2,), lambda i: i)
],
out_specs=pl.BlockSpec((2,), lambda i: i),
grid=(4,))
add(x, y)
範本化的矩陣乘法#
在這個範例中,我們透過對輸入陣列的行和列區塊進行展開累積,來計算輸出的分塊。我們使用高階函數將激活函數內聯到核心的主體中,以便我們可以發射一個融合核心。
def matmul_kernel(x_ref, y_ref, o_ref, *, activation, block_k):
acc = jnp.zeros((x_ref.shape[0], y_ref.shape[1]), jnp.float32)
for k in range(x_ref.shape[1] // block_k):
x = x_ref[:, k*block_k:(k+1)*block_k]
y = y_ref[k*block_k:(k+1)*block_k, :]
acc += x @ y
o_ref[:, :] = activation(acc).astype(o_ref.dtype)
x, y = jnp.ones((512, 256)), jnp.ones((256, 1024))
block_shape = 128, 256, 128
@partial(jax.jit, static_argnames=["block_shape", "activation"])
def matmul(x, y, *, block_shape, activation):
block_m, block_n, block_k = block_shape
fused_matmul = pl.pallas_call(
partial(matmul_kernel, block_k=block_k, activation=activation),
out_shape=jax.ShapeDtypeStruct((x.shape[0], y.shape[1],), jnp.float32),
in_specs=[
pl.BlockSpec((block_m, x.shape[1]), lambda i, j: (i, 0)),
pl.BlockSpec((y.shape[0], block_n), lambda i, j: (0, j))
],
out_specs=pl.BlockSpec((block_m, block_n), lambda i, j: (i, j)),
grid=(4, 4),
)
return fused_matmul(x, y)
z = matmul(x, y, block_shape=block_shape, activation=jax.nn.gelu)
降低 Pallas#
在使用者表達他們的 Pallas 核心之後,我們會根據目標後端將它們降低到不同的表示形式。在 GPU 上,我們將 Pallas 降低到 Triton IR,而在 TPU 上,我們將 Pallas 降低到 Mosaic。
將 Pallas 降低到 Triton 以用於 GPU#
將 Pallas 降低到 Triton 很簡單,因為 Pallas 在設計時就考慮到 Triton 作為目標語言。 Pallas 和 Triton 之間的主要區別在於 Triton 沒有 BlockSpecs 的概念,並且在執行記憶體載入和儲存時使用指標而不是索引。
Triton 在其語言中支援指標作為陣列元素類型,並且在 Triton 中,您可以從指標陣列載入和儲存到指標陣列。在 Pallas 中,當給定一個 (4, 5) 形狀的 Ref, x_ref,然後像 x_ref[3, 2] 這樣做時,我們需要將其降低為計算 x_ref 中適當的 row-major 位置的 Triton 指標(即,執行 5 * 3 + 2 * 1)。同樣地,當我們將切片降低到 Triton 時,例如 x_ref[4, :],我們需要產生一個指標陣列 5 * 4 + jnp.arange(3)。
除此之外,降低到 Triton 相當簡單。 JAX 點積可以降低到 Triton 點積,而 JAX 一元原語則降低到其 Triton 等效項。 Triton 的原子操作通過新的 Pallas 原子原語降低。
將 Pallas 降低到 Mosaic 以用於 TPU#
Mosaic 使用(主要)標準方言 MLIR 並發射 LLO 以編譯用於 TPU。 Pallas 可以通過將 JAX 原語翻譯為 MLIR(主要是 vector 和 arith 方言)來降低到 Mosaic。 BlockSpecs 可以轉換為管線排程(即 Mosaic 中的 transform_funcs)。
轉換 Pallas#
一個自然的問題是 JAX 轉換如何與 Pallas 核心互動? 主要有兩種方式:Pallas 核心內部的轉換和 Pallas 核心外部的轉換。
Pallas 核心內部的轉換實際上應該「正常運作」,只要我們能夠降低轉換後的程式碼。 例如,我們可以在 JAX 核心內部使用 jax.grad(jnp.sin)(...),因為我們可以將 cos 降低到 Triton 和 Mosaic。 然而,我們可能無法降低 jax.vmap(lax.dynamic_slice),因為它可能會變成我們無法降低的 gather。
從外部 JAX 程式轉換 Pallas 核心可能是更有趣的情況。 我們如何處理諸如 vmap(pallas_call) 和 grad(pallas_call) 之類的事情?
vmap-of-pallas_call#
vmap 自動向量化 JAX 程式。 雖然核心作者可能希望精確控制批次核心的行為與其非批次變體有何不同,但我們可以為 pallas_call 提供合理的預設 vmap 規則,同時提供 jax.custom_vmap 自訂機制。 當 pallas_call 被 vmap-ed 時,我們擴增 pallas_call 以具有對應於新批次維度的額外網格維度,並轉換 BlockSpecs 以處理沿該維度的索引。
grad-of-pallas_call#
grad 的 pallas_call 啟用核心的自動微分。 jax.grad 分解為三個不同轉換的應用:jvp, partial_eval 和 transpose。 原則上,當為 pallas_call 實作這些規則時,我們可以重複使用 JAX 的大部分基礎設施(因為它的行為很像現有的 JAX 高階原語)。
然而,由於記憶體存取如何轉置,核心的自動微分可能會導致效能下降。 如果我們編寫一個具有重疊且並行讀取和不相交但並行寫入的 GPU 核心,我們會自動將其轉置為一個具有重疊但並行寫入(以原子方式完成時速度很慢)和不相交且並行讀取的核心。 為了發射一個更好地利用共享記憶體並行性的核心,我們需要重新排序迴圈並更改核心的向量化方式。 不幸的是,我們在 Pallas 中沒有適合這種情況的程式表示形式。 有效自動微分核心的一個潛在方向是探索不同的表示形式,也許是像 Dex 中的那種。 我們也可以看看 Enzyme 如何處理這個問題。 然而,Pallas 核心的 AD 對於一類有效執行轉置的核心(例如元素級核心)可能仍然有用。
但總體而言,jax.custom_vjp 是一個可行的應急方案,用於表達可與 jax.grad 協同運作的 Pallas 核心。
其他轉換#
我們可以想像其他 JAX 轉換應用於我們尚未明確探索的 Pallas 核心。 例如,checkify 是一種執行功能性錯誤處理的 JAX 轉換。 我們可以想像將 checkify 與 pallas_call 一起使用,以允許從 GPU 核心中導出錯誤代碼,以指示是否產生了 OOB 存取或 NaN。
另一個要整合的潛在轉換是 custom_partitioning,以啟用可自動分區的核心以與 pjit 一起使用。