自訂導數規則#
![]()

在 JAX 中,有兩種方式可以定義微分規則
使用
jax.custom_jvp和jax.custom_vjp為已可進行 JAX 轉換的 Python 函式定義自訂微分規則;以及定義新的
core.Primitive實例以及其所有轉換規則,例如呼叫來自其他系統 (如求解器、模擬器或一般數值計算系統) 的函式。
本筆記本是關於 #1。若要改為閱讀關於 #2 的內容,請參閱關於新增基本運算的筆記本。
如需 JAX 自動微分 API 的簡介,請參閱自動微分食譜。本筆記本假設您已熟悉 jax.jvp 和 jax.grad,以及 JVP 和 VJP 的數學意義。
摘要#
使用 jax.custom_jvp 的自訂 JVP#
import jax.numpy as jnp
from jax import custom_jvp
@custom_jvp
def f(x, y):
return jnp.sin(x) * y
@f.defjvp
def f_jvp(primals, tangents):
x, y = primals
x_dot, y_dot = tangents
primal_out = f(x, y)
tangent_out = jnp.cos(x) * x_dot * y + jnp.sin(x) * y_dot
return primal_out, tangent_out
from jax import jvp, grad
print(f(2., 3.))
y, y_dot = jvp(f, (2., 3.), (1., 0.))
print(y)
print(y_dot)
print(grad(f)(2., 3.))
2.7278922
2.7278922
-1.2484405
-1.2484405
# Equivalent alternative using the defjvps convenience wrapper
@custom_jvp
def f(x, y):
return jnp.sin(x) * y
f.defjvps(lambda x_dot, primal_out, x, y: jnp.cos(x) * x_dot * y,
lambda y_dot, primal_out, x, y: jnp.sin(x) * y_dot)
print(f(2., 3.))
y, y_dot = jvp(f, (2., 3.), (1., 0.))
print(y)
print(y_dot)
print(grad(f)(2., 3.))
2.7278922
2.7278922
-1.2484405
-1.2484405
使用 jax.custom_vjp 的自訂 VJP#
from jax import custom_vjp
@custom_vjp
def f(x, y):
return jnp.sin(x) * y
def f_fwd(x, y):
# Returns primal output and residuals to be used in backward pass by f_bwd.
return f(x, y), (jnp.cos(x), jnp.sin(x), y)
def f_bwd(res, g):
cos_x, sin_x, y = res # Gets residuals computed in f_fwd
return (cos_x * g * y, sin_x * g)
f.defvjp(f_fwd, f_bwd)
print(grad(f)(2., 3.))
-1.2484405
範例問題#
為了瞭解 jax.custom_jvp 和 jax.custom_vjp 旨在解決哪些問題,讓我們來看幾個範例。jax.custom_jvp 和 jax.custom_vjp API 的更完整介紹在下一節中。
數值穩定性#
jax.custom_jvp 的一個應用是提高微分的數值穩定性。
假設我們要撰寫一個名為 log1pexp 的函式,其計算 \(x \mapsto \log ( 1 + e^x )\)。我們可以使用 jax.numpy 來撰寫
def log1pexp(x):
return jnp.log(1. + jnp.exp(x))
log1pexp(3.)
Array(3.0485873, dtype=float32, weak_type=True)
由於它是以 jax.numpy 撰寫的,因此它是可進行 JAX 轉換的
from jax import jit, grad, vmap
print(jit(log1pexp)(3.))
print(jit(grad(log1pexp))(3.))
print(vmap(jit(grad(log1pexp)))(jnp.arange(3.)))
3.0485873
0.95257413
[0.5 0.7310586 0.8807971]
但這裡潛藏著數值穩定性問題
print(grad(log1pexp)(100.))
nan
這似乎不太對!畢竟,\(x \mapsto \log (1 + e^x)\) 的導數是 \(x \mapsto \frac{e^x}{1 + e^x}\),因此對於較大的 \(x\) 值,我們預期值大約為 1。
我們可以透過查看梯度計算的 jaxpr 來更深入地瞭解正在發生的情況
from jax import make_jaxpr
make_jaxpr(grad(log1pexp))(100.)
{ lambda ; a:f32[]. let
b:f32[] = exp a
c:f32[] = add 1.0 b
_:f32[] = log c
d:f32[] = div 1.0 c
e:f32[] = mul d b
in (e,) }
逐步執行 jaxpr 的評估方式,我們可以看到最後一行會涉及將浮點數學會四捨五入為 0 和 \(\infty\) 的值相乘,這絕不是一個好主意。也就是說,我們實際上是在為較大的 x 評估 lambda x: (1 / (1 + jnp.exp(x))) * jnp.exp(x),這實際上變成了 0. * jnp.inf。
與其產生如此大和小的值,並希望浮點數不一定能提供的抵銷,我們寧願將導數函式表示為數值上更穩定的程式。特別是,我們可以撰寫一個程式,更精確地評估相等的數學式 \(1 - \frac{1}{1 + e^x}\),而沒有明顯的抵銷。
這個問題很有趣,因為即使我們對 log1pexp 的定義已經可以進行 JAX 微分 (並使用 jit、vmap 等轉換),但我們對將標準自動微分規則套用至組成 log1pexp 的基本運算並組合結果感到不滿意。相反地,我們想要指定整個函式 log1pexp 應如何微分 (作為一個單元),並因此更好地安排這些指數。
這是已可進行 JAX 轉換的 Python 函式的自訂導數規則的一個應用:指定複合函式應如何微分,同時仍將其原始 Python 定義用於其他轉換 (如 jit、vmap 等)。
以下是使用 jax.custom_jvp 的解決方案
from jax import custom_jvp
@custom_jvp
def log1pexp(x):
return jnp.log(1. + jnp.exp(x))
@log1pexp.defjvp
def log1pexp_jvp(primals, tangents):
x, = primals
x_dot, = tangents
ans = log1pexp(x)
ans_dot = (1 - 1/(1 + jnp.exp(x))) * x_dot
return ans, ans_dot
print(grad(log1pexp)(100.))
1.0
print(jit(log1pexp)(3.))
print(jit(grad(log1pexp))(3.))
print(vmap(jit(grad(log1pexp)))(jnp.arange(3.)))
3.0485873
0.95257413
[0.5 0.7310586 0.8807971]
以下是 defjvps 便利包裝函式,用於表達相同的內容
@custom_jvp
def log1pexp(x):
return jnp.log(1. + jnp.exp(x))
log1pexp.defjvps(lambda t, ans, x: (1 - 1/(1 + jnp.exp(x))) * t)
print(grad(log1pexp)(100.))
print(jit(log1pexp)(3.))
print(jit(grad(log1pexp))(3.))
print(vmap(jit(grad(log1pexp)))(jnp.arange(3.)))
1.0
3.0485873
0.95257413
[0.5 0.7310586 0.8807971]
強制微分慣例#
一個相關的應用是強制執行微分慣例,可能在邊界處。
考慮函式 \(f : \mathbb{R}_+ \to \mathbb{R}_+\),其中 \(f(x) = \frac{x}{1 + \sqrt{x}}\),我們取 \(\mathbb{R}_+ = [0, \infty)\)。我們可以將 \(f\) 實作為如下程式
def f(x):
return x / (1 + jnp.sqrt(x))
作為 \(\mathbb{R}\) (完整的實數線) 上的數學函式,\(f\) 在零處不可微分 (因為從左側不存在定義導數的極限)。相對應地,自動微分會產生 nan 值
print(grad(f)(0.))
nan
但在數學上,如果我們將 \(f\) 視為 \(\mathbb{R}_+\) 上的函式,則它在 0 處是可微分的 [Rudin 的數學分析原理定義 5.1,或 Tao 的分析 I 第 3 版定義 10.1.1 和範例 10.1.6]。或者,我們可以說作為一個慣例,我們想要考慮來自右側的方向導數。因此,Python 函式 grad(f) 在 0.0 處傳回一個合理的數值,即 1.0。依預設,JAX 的微分機制假設所有函式都在 \(\mathbb{R}\) 上定義,因此不會在此處產生 1.0。
我們可以使用自訂 JVP 規則!特別是,我們可以根據 \(\mathbb{R}_+\) 上的導數函式 \(x \mapsto \frac{\sqrt{x} + 2}{2(\sqrt{x} + 1)^2}\) 來定義 JVP 規則,
@custom_jvp
def f(x):
return x / (1 + jnp.sqrt(x))
@f.defjvp
def f_jvp(primals, tangents):
x, = primals
x_dot, = tangents
ans = f(x)
ans_dot = ((jnp.sqrt(x) + 2) / (2 * (jnp.sqrt(x) + 1)**2)) * x_dot
return ans, ans_dot
print(grad(f)(0.))
1.0
以下是便利包裝函式版本
@custom_jvp
def f(x):
return x / (1 + jnp.sqrt(x))
f.defjvps(lambda t, ans, x: ((jnp.sqrt(x) + 2) / (2 * (jnp.sqrt(x) + 1)**2)) * t)
print(grad(f)(0.))
1.0
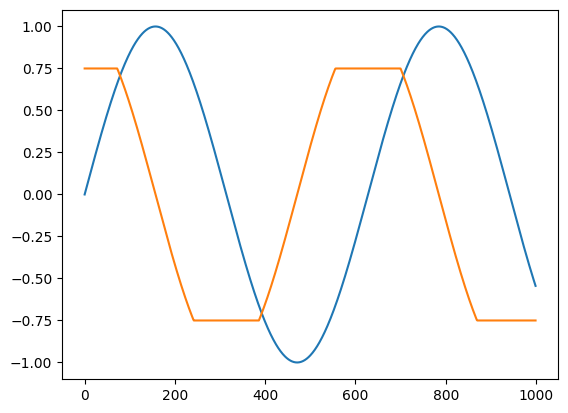
梯度裁剪#
雖然在某些情況下,我們想要表達數學微分計算,但在其他情況下,我們甚至可能想要跳脫數學,以調整自動微分執行的計算。一個典型的範例是反向模式梯度裁剪。
對於梯度裁剪,我們可以將 jnp.clip 與 jax.custom_vjp 僅反向模式規則一起使用
from functools import partial
from jax import custom_vjp
@custom_vjp
def clip_gradient(lo, hi, x):
return x # identity function
def clip_gradient_fwd(lo, hi, x):
return x, (lo, hi) # save bounds as residuals
def clip_gradient_bwd(res, g):
lo, hi = res
return (None, None, jnp.clip(g, lo, hi)) # use None to indicate zero cotangents for lo and hi
clip_gradient.defvjp(clip_gradient_fwd, clip_gradient_bwd)
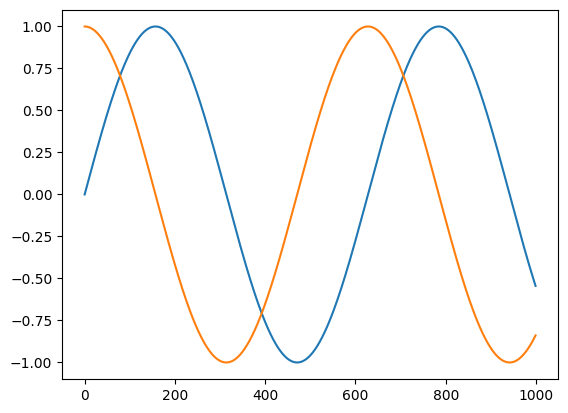
import matplotlib.pyplot as plt
from jax import vmap
t = jnp.linspace(0, 10, 1000)
plt.plot(jnp.sin(t))
plt.plot(vmap(grad(jnp.sin))(t))
[<matplotlib.lines.Line2D at 0x7ff5e5865030>]
def clip_sin(x):
x = clip_gradient(-0.75, 0.75, x)
return jnp.sin(x)
plt.plot(clip_sin(t))
plt.plot(vmap(grad(clip_sin))(t))
[<matplotlib.lines.Line2D at 0x7ff5e56db310>]
Python 除錯#
另一個應用是受到開發工作流程而非數值化的驅動,是在反向模式自動微分的反向傳遞中設定 pdb 除錯器追蹤。
當嘗試追蹤 nan 執行階段錯誤的來源,或只是仔細檢查正在傳播的共切線 (梯度) 值時,在反向傳遞中對應於原始計算中特定點的位置插入除錯器可能會很有用。您可以使用 jax.custom_vjp 來執行此操作。
我們將把範例延後到下一節。
迭代實作的隱含函數微分#
這個範例深入探討了數學細節!
jax.custom_vjp 的另一個應用是對可進行 JAX 轉換 (透過 jit、vmap 等) 但由於某些原因而無法有效進行 JAX 微分的函式進行反向模式微分,原因可能是因為它們涉及 lax.while_loop。(無法產生有效計算 XLA HLO While 迴圈反向模式導數的 XLA HLO 程式,因為這會需要具有無界記憶體使用的程式,這無法在 XLA HLO 中表示,至少在沒有透過 infeed/outfeed 的副作用互動的情況下無法表示。)
例如,考慮這個 fixed_point 常式,它透過在 while_loop 中迭代套用函式來計算不動點
from jax.lax import while_loop
def fixed_point(f, a, x_guess):
def cond_fun(carry):
x_prev, x = carry
return jnp.abs(x_prev - x) > 1e-6
def body_fun(carry):
_, x = carry
return x, f(a, x)
_, x_star = while_loop(cond_fun, body_fun, (x_guess, f(a, x_guess)))
return x_star
這是一個迭代程序,用於數值求解 \(x = f(a, x)\) 的 \(x\) 方程式,方法是迭代 \(x_{t+1} = f(a, x_t)\) 直到 \(x_{t+1}\) 充分接近 \(x_t\)。\(x^*\) 結果取決於參數 \(a\),因此我們可以認為存在一個函式 \(a \mapsto x^*(a)\),該函式由方程式 \(x = f(a, x)\) 隱含定義。
我們可以使用 fixed_point 執行迭代程序以達到收斂,例如執行牛頓法來計算平方根,同時僅執行加法、乘法和除法
def newton_sqrt(a):
update = lambda a, x: 0.5 * (x + a / x)
return fixed_point(update, a, a)
print(newton_sqrt(2.))
1.4142135
我們也可以 vmap 或 jit 函式
print(jit(vmap(newton_sqrt))(jnp.array([1., 2., 3., 4.])))
[1. 1.4142135 1.7320509 2. ]
由於 while_loop,我們無法套用反向模式自動微分,但事實證明我們無論如何都不想這樣做:與其透過 fixed_point 及其所有迭代的實作進行微分,不如利用數學結構來執行更有效率的記憶體操作 (在本例中也更有效率地執行 FLOP!)。我們可以改為使用隱含函數定理 [Bertsekas 的非線性規劃第 2 版的命題 A.25],該定理保證 (在某些條件下) 我們即將使用的數學物件的存在。從本質上講,我們在解處線性化,並迭代求解這些線性方程式,以計算我們想要的導數。
再次考慮方程式 \(x = f(a, x)\) 和函式 \(x^*\)。我們想要評估向量-雅可比矩陣乘積,例如 \(v^\mathsf{T} \mapsto v^\mathsf{T} \partial x^*(a_0)\)。
至少在我們想要微分的點 \(a_0\) 周圍的開放鄰域中,讓我們假設方程式 \(x^*(a) = f(a, x^*(a))\) 對於所有 \(a\) 都成立。由於兩側作為 \(a\) 的函式是相等的,因此它們的導數也必須相等,因此讓我們對兩側進行微分
\(\qquad \partial x^*(a) = \partial_0 f(a, x^*(a)) + \partial_1 f(a, x^*(a)) \partial x^*(a)\).
設定 \(A = \partial_1 f(a_0, x^*(a_0))\) 和 \(B = \partial_0 f(a_0, x^*(a_0))\),我們可以將我們正在尋找的量更簡單地寫成
\(\qquad \partial x^*(a_0) = B + A \partial x^*(a_0)\),
或,透過重新排列,
\(\qquad \partial x^*(a_0) = (I - A)^{-1} B\).
這表示我們可以評估向量-雅可比矩陣乘積,例如
\(\qquad v^\mathsf{T} \partial x^*(a_0) = v^\mathsf{T} (I - A)^{-1} B = w^\mathsf{T} B\),
其中 \(w^\mathsf{T} = v^\mathsf{T} (I - A)^{-1}\),或等效地 \(w^\mathsf{T} = v^\mathsf{T} + w^\mathsf{T} A\),或等效地 \(w^\mathsf{T}\) 是映射 \(u^\mathsf{T} \mapsto v^\mathsf{T} + u^\mathsf{T} A\) 的不動點。最後一個特徵為我們提供了一種以呼叫 fixed_point 的形式撰寫 fixed_point 的 VJP 的方法!此外,在展開 \(A\) 和 \(B\) 後,我們可以發現我們只需要評估 \(f\) 在 \((a_0, x^*(a_0))\) 處的 VJP。
以下是重點
from jax import vjp
@partial(custom_vjp, nondiff_argnums=(0,))
def fixed_point(f, a, x_guess):
def cond_fun(carry):
x_prev, x = carry
return jnp.abs(x_prev - x) > 1e-6
def body_fun(carry):
_, x = carry
return x, f(a, x)
_, x_star = while_loop(cond_fun, body_fun, (x_guess, f(a, x_guess)))
return x_star
def fixed_point_fwd(f, a, x_init):
x_star = fixed_point(f, a, x_init)
return x_star, (a, x_star)
def fixed_point_rev(f, res, x_star_bar):
a, x_star = res
_, vjp_a = vjp(lambda a: f(a, x_star), a)
a_bar, = vjp_a(fixed_point(partial(rev_iter, f),
(a, x_star, x_star_bar),
x_star_bar))
return a_bar, jnp.zeros_like(x_star)
def rev_iter(f, packed, u):
a, x_star, x_star_bar = packed
_, vjp_x = vjp(lambda x: f(a, x), x_star)
return x_star_bar + vjp_x(u)[0]
fixed_point.defvjp(fixed_point_fwd, fixed_point_rev)
print(newton_sqrt(2.))
1.4142135
print(grad(newton_sqrt)(2.))
print(grad(grad(newton_sqrt))(2.))
0.35355338
-0.088388346
我們可以透過微分 jnp.sqrt 來檢查我們的答案,jnp.sqrt 使用完全不同的實作
print(grad(jnp.sqrt)(2.))
print(grad(grad(jnp.sqrt))(2.))
0.35355338
-0.08838835
此方法的限制在於引數 f 無法封閉任何涉及微分的值。也就是說,您可能會注意到我們在 fixed_point 的引數清單中明確保留了參數 a。對於此用例,請考慮使用低階基本運算 lax.custom_root,它允許在封閉變數中使用自訂求根函式進行微分。
jax.custom_jvp 和 jax.custom_vjp API 的基本用法#
使用 jax.custom_jvp 定義前向模式 (以及間接的反向模式) 規則#
以下是使用 jax.custom_jvp 的典型基本範例,其中的註解使用類似 Haskell 的類型簽章
from jax import custom_jvp
import jax.numpy as jnp
# f :: a -> b
@custom_jvp
def f(x):
return jnp.sin(x)
# f_jvp :: (a, T a) -> (b, T b)
def f_jvp(primals, tangents):
x, = primals
t, = tangents
return f(x), jnp.cos(x) * t
f.defjvp(f_jvp)
<function __main__.f_jvp(primals, tangents)>
from jax import jvp
print(f(3.))
y, y_dot = jvp(f, (3.,), (1.,))
print(y)
print(y_dot)
0.14112
0.14112
-0.9899925
換句話說,我們從一個原始函式 f 開始,它接受類型為 a 的輸入並產生類型為 b 的輸出。我們將其與 JVP 規則函式 f_jvp 相關聯,該函式接受一對輸入,分別代表類型為 a 的原始輸入和類型為 T a 的對應切線輸入,並產生一對輸出,分別代表類型為 b 的原始輸出和類型為 T b 的切線輸出。切線輸出應為切線輸入的線性函式。
您也可以使用 f.defjvp 作為裝飾器,如下所示
@custom_jvp
def f(x):
...
@f.defjvp
def f_jvp(primals, tangents):
...
即使我們僅定義了 JVP 規則而未定義 VJP 規則,我們也可以在 f 上使用前向和反向模式微分。JAX 將自動轉置來自我們自訂 JVP 規則的切線值線性計算,以計算 VJP,其效率與我們手動撰寫規則時相同
from jax import grad
print(grad(f)(3.))
print(grad(grad(f))(3.))
-0.9899925
-0.14112
為了使自動轉置能夠運作,JVP 規則的輸出切線必須是輸入切線的線性函式。否則會引發轉置錯誤。
多個引數的運作方式如下
@custom_jvp
def f(x, y):
return x ** 2 * y
@f.defjvp
def f_jvp(primals, tangents):
x, y = primals
x_dot, y_dot = tangents
primal_out = f(x, y)
tangent_out = 2 * x * y * x_dot + x ** 2 * y_dot
return primal_out, tangent_out
print(grad(f)(2., 3.))
12.0
defjvps 便利包裝函式可讓我們為每個引數分別定義 JVP,然後分別計算結果並將其加總
@custom_jvp
def f(x):
return jnp.sin(x)
f.defjvps(lambda t, ans, x: jnp.cos(x) * t)
print(grad(f)(3.))
-0.9899925
以下是具有多個引數的 defjvps 範例
@custom_jvp
def f(x, y):
return x ** 2 * y
f.defjvps(lambda x_dot, primal_out, x, y: 2 * x * y * x_dot,
lambda y_dot, primal_out, x, y: x ** 2 * y_dot)
print(grad(f)(2., 3.))
print(grad(f, 0)(2., 3.)) # same as above
print(grad(f, 1)(2., 3.))
12.0
12.0
4.0
作為簡寫,使用 defjvps 時,您可以傳遞 None 值來表示特定參數的 JVP 為零
@custom_jvp
def f(x, y):
return x ** 2 * y
f.defjvps(lambda x_dot, primal_out, x, y: 2 * x * y * x_dot,
None)
print(grad(f)(2., 3.))
print(grad(f, 0)(2., 3.)) # same as above
print(grad(f, 1)(2., 3.))
12.0
12.0
0.0
呼叫帶有關鍵字參數的 jax.custom_jvp 函數,或編寫帶有預設參數的 jax.custom_jvp 函數定義,兩者都是允許的,只要它們可以根據標準函式庫 inspect.signature 機制檢索到的函數簽名,明確地映射到位置參數即可。
當您不執行微分時,函數 f 的呼叫方式就像它沒有被 jax.custom_jvp 修飾一樣
@custom_jvp
def f(x):
print('called f!') # a harmless side-effect
return jnp.sin(x)
@f.defjvp
def f_jvp(primals, tangents):
print('called f_jvp!') # a harmless side-effect
x, = primals
t, = tangents
return f(x), jnp.cos(x) * t
from jax import vmap, jit
print(f(3.))
called f!
0.14112
print(vmap(f)(jnp.arange(3.)))
print(jit(f)(3.))
called f!
[0. 0.84147096 0.9092974 ]
called f!
0.14112
自訂 JVP 規則在微分期間被調用,無論是前向或反向
y, y_dot = jvp(f, (3.,), (1.,))
print(y_dot)
called f_jvp!
called f!
-0.9899925
print(grad(f)(3.))
called f_jvp!
called f!
-0.9899925
請注意,f_jvp 呼叫 f 來計算原始輸出。在更高階微分的上下文中,每次應用微分轉換都將使用自訂 JVP 規則,當且僅當該規則呼叫原始的 f 來計算原始輸出時。(這代表一種基本的權衡,我們無法利用規則中 f 評估的中間值,並且 讓該規則應用於所有更高階微分。)
grad(grad(f))(3.)
called f_jvp!
called f_jvp!
called f!
Array(-0.14112, dtype=float32, weak_type=True)
您可以將 Python 控制流程與 jax.custom_jvp 一起使用
@custom_jvp
def f(x):
if x > 0:
return jnp.sin(x)
else:
return jnp.cos(x)
@f.defjvp
def f_jvp(primals, tangents):
x, = primals
x_dot, = tangents
ans = f(x)
if x > 0:
return ans, 2 * x_dot
else:
return ans, 3 * x_dot
print(grad(f)(1.))
print(grad(f)(-1.))
2.0
3.0
使用 jax.custom_vjp 來定義僅限於自訂反向模式的規則#
雖然 jax.custom_jvp 足以控制前向模式和(透過 JAX 的自動轉置)反向模式的微分行為,但在某些情況下,我們可能希望直接控制 VJP 規則,例如在上面提出的後兩個範例問題中。我們可以透過 jax.custom_vjp 來做到這一點
from jax import custom_vjp
import jax.numpy as jnp
# f :: a -> b
@custom_vjp
def f(x):
return jnp.sin(x)
# f_fwd :: a -> (b, c)
def f_fwd(x):
return f(x), jnp.cos(x)
# f_bwd :: (c, CT b) -> CT a
def f_bwd(cos_x, y_bar):
return (cos_x * y_bar,)
f.defvjp(f_fwd, f_bwd)
from jax import grad
print(f(3.))
print(grad(f)(3.))
0.14112
-0.9899925
換句話說,我們再次從原始函數 f 開始,它接受 a 類型的輸入並產生 b 類型的輸出。我們將其與兩個函數 f_fwd 和 f_bwd 關聯起來,它們描述了如何分別執行反向模式自動微分的前向和反向傳遞。
函數 f_fwd 描述了前向傳遞,不僅包括原始計算,還包括要保存哪些值以供反向傳遞使用。它的輸入簽名與原始函數 f 的輸入簽名非常相似,因為它接受 a 類型的原始輸入。但作為輸出,它產生一個 pair,其中第一個元素是原始輸出 b,第二個元素是要儲存以供反向傳遞使用的任何 c 類型的「殘差」資料。(第二個輸出類似於 PyTorch 的 save_for_backward 機制。)
函數 f_bwd 描述了反向傳遞。它接受兩個輸入,其中第一個是 f_fwd 產生的 c 類型的殘差資料,第二個是與原始函數輸出對應的 CT b 類型的輸出餘切。它產生一個 CT a 類型的輸出,表示與原始函數輸入對應的餘切。特別是,f_bwd 的輸出必須是一個序列(例如 tuple),其長度等於原始函數的參數數量。
因此,多個參數的工作方式如下
from jax import custom_vjp
@custom_vjp
def f(x, y):
return jnp.sin(x) * y
def f_fwd(x, y):
return f(x, y), (jnp.cos(x), jnp.sin(x), y)
def f_bwd(res, g):
cos_x, sin_x, y = res
return (cos_x * g * y, sin_x * g)
f.defvjp(f_fwd, f_bwd)
print(grad(f)(2., 3.))
-1.2484405
呼叫帶有關鍵字參數的 jax.custom_vjp 函數,或編寫帶有預設參數的 jax.custom_vjp 函數定義,兩者都是允許的,只要它們可以根據標準函式庫 inspect.signature 機制檢索到的函數簽名,明確地映射到位置參數即可。
與 jax.custom_jvp 一樣,如果未應用微分,則不會調用由 f_fwd 和 f_bwd 組成的自訂 VJP 規則。如果函數被評估,或使用 jit、vmap 或其他非微分轉換進行轉換,則只會呼叫 f。
@custom_vjp
def f(x):
print("called f!")
return jnp.sin(x)
def f_fwd(x):
print("called f_fwd!")
return f(x), jnp.cos(x)
def f_bwd(cos_x, y_bar):
print("called f_bwd!")
return (cos_x * y_bar,)
f.defvjp(f_fwd, f_bwd)
print(f(3.))
called f!
0.14112
print(grad(f)(3.))
called f_fwd!
called f!
called f_bwd!
-0.9899925
y, f_vjp = vjp(f, 3.)
print(y)
called f_fwd!
called f!
0.14112
print(f_vjp(1.))
called f_bwd!
(Array(-0.9899925, dtype=float32, weak_type=True),)
前向模式自動微分不能用於 jax.custom_vjp 函數,並且會引發錯誤
from jax import jvp
try:
jvp(f, (3.,), (1.,))
except TypeError as e:
print('ERROR! {}'.format(e))
called f_fwd!
called f!
ERROR! can't apply forward-mode autodiff (jvp) to a custom_vjp function.
如果您想同時使用前向模式和反向模式,請改用 jax.custom_jvp。
我們可以將 jax.custom_vjp 與 pdb 一起使用,以便在反向傳遞中插入除錯器追蹤
import pdb
@custom_vjp
def debug(x):
return x # acts like identity
def debug_fwd(x):
return x, x
def debug_bwd(x, g):
pdb.set_trace()
return g
debug.defvjp(debug_fwd, debug_bwd)
def foo(x):
y = x ** 2
y = debug(y) # insert pdb in corresponding backward pass step
return jnp.sin(y)
jax.grad(foo)(3.)
> <ipython-input-113-b19a2dc1abf7>(12)debug_bwd()
-> return g
(Pdb) p x
Array(9., dtype=float32)
(Pdb) p g
Array(-0.91113025, dtype=float32)
(Pdb) q
更多功能和細節#
使用 list / tuple / dict 容器(和其他 pytree)#
您應該預期標準 Python 容器(如 list、tuple、namedtuple 和 dict)以及這些容器的巢狀版本都能正常運作。一般來說,任何 pytree 都是允許的,只要它們的結構根據類型約束保持一致即可。
這是一個關於 jax.custom_jvp 的人為範例
from collections import namedtuple
Point = namedtuple("Point", ["x", "y"])
@custom_jvp
def f(pt):
x, y = pt.x, pt.y
return {'a': x ** 2,
'b': (jnp.sin(x), jnp.cos(y))}
@f.defjvp
def f_jvp(primals, tangents):
pt, = primals
pt_dot, = tangents
ans = f(pt)
ans_dot = {'a': 2 * pt.x * pt_dot.x,
'b': (jnp.cos(pt.x) * pt_dot.x, -jnp.sin(pt.y) * pt_dot.y)}
return ans, ans_dot
def fun(pt):
dct = f(pt)
return dct['a'] + dct['b'][0]
pt = Point(1., 2.)
print(f(pt))
{'a': 1.0, 'b': (Array(0.84147096, dtype=float32, weak_type=True), Array(-0.41614684, dtype=float32, weak_type=True))}
print(grad(fun)(pt))
Point(x=Array(2.5403023, dtype=float32, weak_type=True), y=Array(0., dtype=float32, weak_type=True))
以及一個關於 jax.custom_vjp 的類似人為範例
@custom_vjp
def f(pt):
x, y = pt.x, pt.y
return {'a': x ** 2,
'b': (jnp.sin(x), jnp.cos(y))}
def f_fwd(pt):
return f(pt), pt
def f_bwd(pt, g):
a_bar, (b0_bar, b1_bar) = g['a'], g['b']
x_bar = 2 * pt.x * a_bar + jnp.cos(pt.x) * b0_bar
y_bar = -jnp.sin(pt.y) * b1_bar
return (Point(x_bar, y_bar),)
f.defvjp(f_fwd, f_bwd)
def fun(pt):
dct = f(pt)
return dct['a'] + dct['b'][0]
pt = Point(1., 2.)
print(f(pt))
{'a': 1.0, 'b': (Array(0.84147096, dtype=float32, weak_type=True), Array(-0.41614684, dtype=float32, weak_type=True))}
print(grad(fun)(pt))
Point(x=Array(2.5403023, dtype=float32, weak_type=True), y=Array(-0., dtype=float32, weak_type=True))
處理不可微分的參數#
某些用例,例如最後一個範例問題,需要將不可微分的參數(如函數值參數)傳遞給具有自訂微分規則的函數,並將這些參數也傳遞給規則本身。在 fixed_point 的情況下,函數參數 f 就是這樣一個不可微分的參數。jax.experimental.odeint 也會出現類似的情況。
jax.custom_jvp 與 nondiff_argnums#
使用 jax.custom_jvp 的可選 nondiff_argnums 參數來指示這些參數。以下是一個關於 jax.custom_jvp 的範例
from functools import partial
@partial(custom_jvp, nondiff_argnums=(0,))
def app(f, x):
return f(x)
@app.defjvp
def app_jvp(f, primals, tangents):
x, = primals
x_dot, = tangents
return f(x), 2. * x_dot
print(app(lambda x: x ** 3, 3.))
27.0
print(grad(app, 1)(lambda x: x ** 3, 3.))
2.0
請注意這裡的陷阱:無論這些參數在參數列表中的哪個位置出現,它們都會被放置在相應 JVP 規則簽名的開頭。這是另一個範例
@partial(custom_jvp, nondiff_argnums=(0, 2))
def app2(f, x, g):
return f(g((x)))
@app2.defjvp
def app2_jvp(f, g, primals, tangents):
x, = primals
x_dot, = tangents
return f(g(x)), 3. * x_dot
print(app2(lambda x: x ** 3, 3., lambda y: 5 * y))
3375.0
print(grad(app2, 1)(lambda x: x ** 3, 3., lambda y: 5 * y))
3.0
jax.custom_vjp 與 nondiff_argnums#
對於 jax.custom_vjp 也存在類似的選項,並且類似地,慣例是將不可微分的參數作為第一個參數傳遞給 _bwd 規則,無論它們在原始函數的簽名中的哪個位置出現。_fwd 規則的簽名保持不變 - 它與原始函數的簽名相同。以下是一個範例
@partial(custom_vjp, nondiff_argnums=(0,))
def app(f, x):
return f(x)
def app_fwd(f, x):
return f(x), x
def app_bwd(f, x, g):
return (5 * g,)
app.defvjp(app_fwd, app_bwd)
print(app(lambda x: x ** 2, 4.))
16.0
print(grad(app, 1)(lambda x: x ** 2, 4.))
5.0
有關其他使用範例,請參閱上面的 fixed_point。
您不需要對陣列值參數使用 nondiff_argnums,例如具有整數 dtype 的參數。相反,nondiff_argnums 應僅用於不對應於 JAX 類型(基本上不對應於陣列類型)的參數值,例如 Python 可調用物件或字串。如果 JAX 偵測到由 nondiff_argnums 指示的參數包含 JAX Tracer,則會引發錯誤。上面的 clip_gradient 函數是不對整數 dtype 陣列參數使用 nondiff_argnums 的一個很好的例子。